Syniti, Infinite Potential Unlocked

Hadoop-Datenintegration - einfach machen
Vereinfachen Sie Ihre Replikationsprozesse nach Hadoop
Datenaktualisierungen in Echtzeit mit Syniti Data Replication (ehemals DBMoto)
Datenreplikation für Hadoop
Hadoop ist ein Open Source-System zum Speichern, Verarbeiten und Analysieren großer Datenmengen. Mit Syniti Data Replication können Sie Daten aus relationalen Datenbanken replizieren und das Hadoop HDFS-Dateisystem auf dem neuesten Stand halten.
Big Data ist derzeit einer der Modebegriffe. Big Data ist aber nicht nur großes Datenvolumen, sondern auch Geschwindigkeit und strukturelle Vielfalt.
Eine Big Data-Architektur besteht aus mehreren Teilen. Üblicherweise werden strukturierte und halbstrukturierte historische Daten in Hadoop (Volumen + Vielfalt) gespeichert. Andererseits wird die Echtzeit-Datenverarbeitung für schnelle Datenanforderungen (Geschwindigkeit + Vielfalt) verwendet.
In Szenarien wie dem vorherigen können Lösungen wie Syniti Data Replication durch ihre Datenintegrationsfunktionen in Echtzeit dabei helfen, die Zugriffsgeschwindigkeit auf aktualisierte Daten zu optimieren.
Syniti Data Replication kann auch mit der Vielfalt helfen, da es eine Vielzahl von Arten oder Datenformaten unterstützt (XML, Bilder, BLOB, etc.) in mehreren Datenbanken gespeichert, wie SQL Server, Oracle, Sybase, DB2, Informix, MySQL, SQL Anywhere usw. unabhängig vom Betriebssystem, unter dem die Datenbanken laufen.
Hauptmerkmale
Replikation von Daten aus einer relationalen Datenbank in Hadoop HDFS
- Sichere Kommunikation über den DDH-Channel
- Verwendet stabile Hadoop-Technologie
- Arbeitet mit allen Versionen von Hadoop
- Ermöglicht Hadoop die Verwaltung der Datenverteilung
- Flexible und konfigurierbare Lösung
Verwenden Sie das Syniti Data Replication Management Center um:
- Quellverbindungen zu RDBMS-Tabellen zu erstellen
- CSV-Zieldateien für RDBMS-Tabellen zu erstellen
- RDBMS-Quellen für Zieldateien zuzuordnen
- Replikationen zu aktivieren
Konfigurieren Sie Syniti Data Replication HBroker und führen ihn aus um:
- Datendateien zu lesen
- SSH-Kanal zu öffnen
- Vorhandene Tabellen falls nötig abzuschneiden
- Daten an HDFS zu senden
Volle technische Unterstützung während der Evaluierung

In Apache® Hadoop-Umgebungen ist keine Programmierung erforderlich

Verschieben Sie strategische Daten in Ihre Apache® Hadoop-Umgebungen in Echtzeit

Zuverlässige und stets aktuelle Daten für Ihre Apache® Hadoop-Systeme

Reduzieren Sie finanzielle Auswirkungen durch Implementierung von Syniti Data Replication in Ihrer Apache® Hadoop-Umgebung
Zwei Arten der Datenreplikation für Hadoop
- Refresh (Snapshot): Alle Daten lesen, benutzerdefinierte Zuordnungsregeln anwenden und das Ergebnis in die Zieldatenbank schreiben
- Mirroring (CDC): Transaktionsreplikation von der Quelle zum Ziel mithilfe der CDC-Technologie, die auf dem Lesen von Transaktionsprotokollen basiert und ein höheres Maß an Präzision und Geschwindigkeit ermöglicht
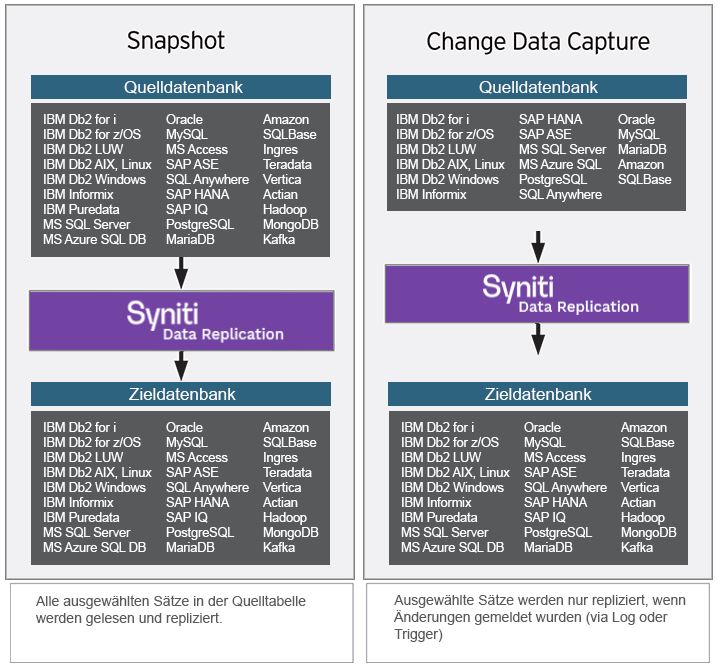
Unterstützte Datenbanken
Testen Sie Syniti Data Replication mit Ihren Hadoop-Systemen
Laden Sie eine Testversion herunter. Technischer Support in diesem Zeitraum inbegriffen.
Systemanforderungen:
Windows Server 2019/2016/2014/2012/2008/2003 | .NET Framework 4.0 oder höher
Windows Server 2019/2016/2014/2012/2008/2003 | .NET Framework 4.0 oder höher